
Failover Clustering

Failover clustering digunakan untuk melindungi ketersediaan (availability) instance pada semua DB SQL Server. Meskipun node server men-share disk atau resource yang sama, tapi hanya satu server yang menjadi pemilik (ownership) untuk membaca dan menulis dari group resource pada waktu tertentu. Jika failover(kegagalan) terjadi, ownership ditransfer ke node lain, dan SQL Server kembali diwaktu yang dibutuhkan untuk membawa database kembali online. Failover biasanya memakan hitungan waktu tidak pasti ,sekitar hitungan detik hingga beberapa menit, tergantung pada ukuran database dan jenis transaksi yang sedang berlangsung selama kegagalan.
Agar database untuk kembali ke kondisi yang siap pakai selama failover harus melalui fase Redo dan Undo, fase Redo untuk men-commit transaksi yang telah tercatat dan fase Undo untuk me-roll back transaksi yang belum tercatat. Pemulihan sistem yang cepat adalah fitur Enterprise Edition yang diperkenalkan pada SQLServer 2005 yang memungkinkan aplikasi untuk mengakses database segera setelah fase Redo selesai. Karena cluster muncul di jaringan sebagai single server (server tunggal), tidak perlu untuk mengarahkan aplikasi ke server yang berbeda selama failover. Pemulihan yang cepat ini membuat proses penanganan kegagalan yang cukup cepat dan tidak mengganggu yang pada akhirnya menghasilkan waktu downtime yang sebentar selama kegagalan.
Jumlah node yang dapat ditambahkan ke cluster tergantung pada edisi sistem operasi (OS) serta edisi SQL Server, dengan maksimal 16 node menggunakan SQL Server 2008 Enterprise Edition yang berjalan pada Windows Server 2008. Failover Clustering hanya didukung dalam Edisi Enterprise dan Standar SQL Server. Jika Anda menggunakan Edisi Standar, Anda dibatasi untuk cluster 2-node.
Karena failover clustering juga tergantung pada OS, Anda harus menyadari keterbatasan untuk setiap edisi OS juga. Windows Server 2008 hanya mendukung penggunaan failover clustering pada Edisi Enterprise, Datacenter, dan Itanium.Windows Server 2008 Enterprise dan Datacenter Edisi kedua mendukung 16-node cluster, sedangkan edisi Itanium hanya mendukung cluster 8-node.
Dalam rangka untuk menyebarkan beban kerja beberapa database di server, setiap node di cluster dapat memiliki ownership dari beberapa resource dan instance SQL Server. Setiap server yang memiliki sumber daya disebut sebagai active node , dan setiap server yang tidak memiliki sumber daya disebut sebagai pasif node.
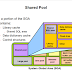
Ada dua tipe dasar konfigurasi cluster: one cluster-node dan multi-node cluster, multi-node berisi dua atau lebih aktif node dengan satu atau lebih pasif node, dan one cluster-node berisi satu node aktif dengan satu atau lebih pasif node. Gambar-1 menunjukkan konfigurasi cluster single-node standar yang biasa disebut sebagai aktif / pasif konfigurasi.
Jadi jika beberapa node aktif memungkinkan Anda untuk memanfaatkan semua server Anda, mengapa tidak akan Anda membuat semua server di cluster aktif? Jawaban: kendala resource(sumber daya). Dalam cluster 2-node, jika salah satu node memiliki kegagalan, node lain yang tersedia harus memproses beban normal serta beban node gagal. Untuk alasan ini, itu(membuat 1 server aktif dan 1 server pasif) dianggap praktek terbaik dalam cluster failover.


Gambar-2 menunjukkan konfigurasi multi-node cluster yang sehat berjalan dengan hanya dua node. Jika Node 1 memiliki kegagalan, seperti yang ditunjukkan pada Gambar-3 Node 2 sekarang bertanggung jawab untuk kedua instance dari SQL Server. Sementara konfigurasi ini secara teknis akan bekerja, jika Node 2 tidak memiliki kapasitas untuk menangani beban kerja dari kedua kasus,server Anda dapat berjalan lambat, akhirnya menyebabkan user kecewa.
Jadi, bagaimana hal ini bekerja? Sebuah sinyal heartbeat dikirim antara node untuk menentukan ketersediaan satu sama lain. Jika salah satu node belum menerima pesan dalam jangka waktu tertentu (jumlah retries), failover dimulai dan node failover utama mengambil kepemilikan sumber daya.
Ini adalah tanggung jawab untuk mempertahankan catatan dari bagian masing-masing node selama proses ini. Pemeriksaan heartbeat dilakukan di tingkat OS serta tingkat SQL Server.
OS yang berada dalam kontak konstan dengan node lain, memeriksa dan ketersediaan server.
Untuk alasan ini, pivate network digunakan pada heartbeat antar node untuk mengurangi kemungkinan failover terjadi karena masalah jaringan yang terkait.
SQL Server mengirimkan pesan yang dikenal sebagai LooksAlive dan IsAlive. LooksAlive adalah melakukan pengecek-an gangguan sekurang-kurangnya setiap 5 detik untuk memastikan layanan. Cek IsAlive berjalan setiap 60 detik dan mengeksekusi query SELECT @@ServerName terhadap node aktif untuk memastikan bahwa SQL Server dapat menanggapi permintaan yang masuk.
Implementasi
Sebelum menginstal SQL Server, yang harus dilakukan adalah memastikan bahwa konfigurasi OS Windows dan hardware telah mendukung teknologi cluster. Salah satu poin/syarat yang berat ketika membuat cluster failover adalah mencari daftar kompatibilitas perangkat keras / Hardware Compatibility List (HCL) untuk memastikan dukungan dan solusi hardware yang diterapkan.
Persyaratan ini telah dihapus pada Windows Server 2008. Sekarang kita bisa menjalan tool validasi cluster yang baru untuk melakukan semua pengecekan requirement(kebutuhan) untuk memastikan berjalannya OS pada konfigurasi yang didukung. Tool validasi cluster tidak hanya digunakan untuk mengkonfirmasi konfigurasi server saja, namun dapat digunakan memecahkan masalah setelah penyiapan juga.
Dari perspektif SQL Server, proses instalasi sangat mudah. Jika Anda yang akrab dengan memasang failover cluster di SQL Server 2005, pada SQL Server 2008 telah benar-benar berubah. Pertama Anda menjalankan instalasi pada satu node untuk membuat satu cluster-node. Maka Anda menjalankan instalasi pada setiap node yang tersisa, memilih opsi Add Node selama setup. Untuk menghapus node dari cluster, Anda menjalankan setup.exe pada server yang perlu menjadi dihapus dan pilih opsi Hapus Node. Proses instalasi baru memungkinkan untuk lebih pengelolaan granular dari node, yang memungkinkan Anda untuk menambah dan menghapus node tanpa membawa menyusuri seluruh cluster. Proses instalasi baru ini juga memungkinkan Anda untuk melakukan patching dan bergulir upgrade dengan downtime minimal.
Jangan takut failover clustering. Dibutuhkan perencanaan ekstra di depan, tetapi sekali telah berhasil dilaksanakan, pengelolaan lingkungan berkerumun benar-benar tidak banyak berbeda dari lingkungan SQL lainnya. Sama seperti contoh SQL telah disampaikan kepada aplikasi di lapisan jaringan virtual, akan disampaikan kepada administrator dengan cara ini juga. Selama Anda menggunakan semua nama maya benar ketika terhubung ke instance SQL, itu akan hanya menjadi administrasi seperti biasa.
Kelebihan dan Kekurangan Failover Clustering
Seperti solusi teknologi lainnya, failover clustering membawa manfaat tertentu, tetapi dengan biaya.
Manfaat failover clustering meliputi berikut ini:
- Kehilangan data nol
- Perlindungan seluruh contoh
- Pemulihan cepat
- Failover otomatis
Harga yang Anda bayar untuk manfaat ini adalah sebagai berikut:
- Failover clustering tidak melindungi terhadap kegagalan disk
- Tidak ada standby database tersedia untuk pelaporan
- Khusus Hardware diperlukan
- Failover clustering umumnya mahal untuk diterapkan
- Tidak ada duplikat data untuk laporan atau pemulihan bencana
Gambar 1
Failover clustering digunakan untuk melindungi ketersediaan (availability) instance pada semua DB SQL Server. Meskipun node server men-share disk atau resource yang sama, tapi hanya satu server yang menjadi pemilik (ownership) untuk membaca dan menulis dari group resource pada waktu tertentu. Jika failover(kegagalan) terjadi, ownership ditransfer ke node lain, dan SQL Server kembali diwaktu yang dibutuhkan untuk membawa database kembali online. Failover biasanya memakan hitungan waktu tidak pasti ,sekitar hitungan detik hingga beberapa menit, tergantung pada ukuran database dan jenis transaksi yang sedang berlangsung selama kegagalan.
Agar database untuk kembali ke kondisi yang siap pakai selama failover harus melalui fase Redo dan Undo, fase Redo untuk men-commit transaksi yang telah tercatat dan fase Undo untuk me-roll back transaksi yang belum tercatat. Pemulihan sistem yang cepat adalah fitur Enterprise Edition yang diperkenalkan pada SQLServer 2005 yang memungkinkan aplikasi untuk mengakses database segera setelah fase Redo selesai. Karena cluster muncul di jaringan sebagai single server (server tunggal), tidak perlu untuk mengarahkan aplikasi ke server yang berbeda selama failover. Pemulihan yang cepat ini membuat proses penanganan kegagalan yang cukup cepat dan tidak mengganggu yang pada akhirnya menghasilkan waktu downtime yang sebentar selama kegagalan.
Jumlah node yang dapat ditambahkan ke cluster tergantung pada edisi sistem operasi (OS) serta edisi SQL Server, dengan maksimal 16 node menggunakan SQL Server 2008 Enterprise Edition yang berjalan pada Windows Server 2008. Failover Clustering hanya didukung dalam Edisi Enterprise dan Standar SQL Server. Jika Anda menggunakan Edisi Standar, Anda dibatasi untuk cluster 2-node.
Karena failover clustering juga tergantung pada OS, Anda harus menyadari keterbatasan untuk setiap edisi OS juga. Windows Server 2008 hanya mendukung penggunaan failover clustering pada Edisi Enterprise, Datacenter, dan Itanium.Windows Server 2008 Enterprise dan Datacenter Edisi kedua mendukung 16-node cluster, sedangkan edisi Itanium hanya mendukung cluster 8-node.
Dalam rangka untuk menyebarkan beban kerja beberapa database di server, setiap node di cluster dapat memiliki ownership dari beberapa resource dan instance SQL Server. Setiap server yang memiliki sumber daya disebut sebagai active node , dan setiap server yang tidak memiliki sumber daya disebut sebagai pasif node.
Ada dua tipe dasar konfigurasi cluster: one cluster-node dan multi-node cluster, multi-node berisi dua atau lebih aktif node dengan satu atau lebih pasif node, dan one cluster-node berisi satu node aktif dengan satu atau lebih pasif node. Gambar-1 menunjukkan konfigurasi cluster single-node standar yang biasa disebut sebagai aktif / pasif konfigurasi.
Jadi jika beberapa node aktif memungkinkan Anda untuk memanfaatkan semua server Anda, mengapa tidak akan Anda membuat semua server di cluster aktif? Jawaban: kendala resource(sumber daya). Dalam cluster 2-node, jika salah satu node memiliki kegagalan, node lain yang tersedia harus memproses beban normal serta beban node gagal. Untuk alasan ini, itu(membuat 1 server aktif dan 1 server pasif) dianggap praktek terbaik dalam cluster failover.
Gambar 2
Gambar 3
Gambar-2 menunjukkan konfigurasi multi-node cluster yang sehat berjalan dengan hanya dua node. Jika Node 1 memiliki kegagalan, seperti yang ditunjukkan pada Gambar-3 Node 2 sekarang bertanggung jawab untuk kedua instance dari SQL Server. Sementara konfigurasi ini secara teknis akan bekerja, jika Node 2 tidak memiliki kapasitas untuk menangani beban kerja dari kedua kasus,server Anda dapat berjalan lambat, akhirnya menyebabkan user kecewa.
Jadi, bagaimana hal ini bekerja? Sebuah sinyal heartbeat dikirim antara node untuk menentukan ketersediaan satu sama lain. Jika salah satu node belum menerima pesan dalam jangka waktu tertentu (jumlah retries), failover dimulai dan node failover utama mengambil kepemilikan sumber daya.
Ini adalah tanggung jawab untuk mempertahankan catatan dari bagian masing-masing node selama proses ini. Pemeriksaan heartbeat dilakukan di tingkat OS serta tingkat SQL Server.
OS yang berada dalam kontak konstan dengan node lain, memeriksa dan ketersediaan server.
Untuk alasan ini, pivate network digunakan pada heartbeat antar node untuk mengurangi kemungkinan failover terjadi karena masalah jaringan yang terkait.
SQL Server mengirimkan pesan yang dikenal sebagai LooksAlive dan IsAlive. LooksAlive adalah melakukan pengecek-an gangguan sekurang-kurangnya setiap 5 detik untuk memastikan layanan. Cek IsAlive berjalan setiap 60 detik dan mengeksekusi query SELECT @@ServerName terhadap node aktif untuk memastikan bahwa SQL Server dapat menanggapi permintaan yang masuk.
Implementasi
Sebelum menginstal SQL Server, yang harus dilakukan adalah memastikan bahwa konfigurasi OS Windows dan hardware telah mendukung teknologi cluster. Salah satu poin/syarat yang berat ketika membuat cluster failover adalah mencari daftar kompatibilitas perangkat keras / Hardware Compatibility List (HCL) untuk memastikan dukungan dan solusi hardware yang diterapkan.
Persyaratan ini telah dihapus pada Windows Server 2008. Sekarang kita bisa menjalan tool validasi cluster yang baru untuk melakukan semua pengecekan requirement(kebutuhan) untuk memastikan berjalannya OS pada konfigurasi yang didukung. Tool validasi cluster tidak hanya digunakan untuk mengkonfirmasi konfigurasi server saja, namun dapat digunakan memecahkan masalah setelah penyiapan juga.
Dari perspektif SQL Server, proses instalasi sangat mudah. Jika Anda yang akrab dengan memasang failover cluster di SQL Server 2005, pada SQL Server 2008 telah benar-benar berubah. Pertama Anda menjalankan instalasi pada satu node untuk membuat satu cluster-node. Maka Anda menjalankan instalasi pada setiap node yang tersisa, memilih opsi Add Node selama setup. Untuk menghapus node dari cluster, Anda menjalankan setup.exe pada server yang perlu menjadi dihapus dan pilih opsi Hapus Node. Proses instalasi baru memungkinkan untuk lebih pengelolaan granular dari node, yang memungkinkan Anda untuk menambah dan menghapus node tanpa membawa menyusuri seluruh cluster. Proses instalasi baru ini juga memungkinkan Anda untuk melakukan patching dan bergulir upgrade dengan downtime minimal.
Jangan takut failover clustering. Dibutuhkan perencanaan ekstra di depan, tetapi sekali telah berhasil dilaksanakan, pengelolaan lingkungan berkerumun benar-benar tidak banyak berbeda dari lingkungan SQL lainnya. Sama seperti contoh SQL telah disampaikan kepada aplikasi di lapisan jaringan virtual, akan disampaikan kepada administrator dengan cara ini juga. Selama Anda menggunakan semua nama maya benar ketika terhubung ke instance SQL, itu akan hanya menjadi administrasi seperti biasa.
Kelebihan dan Kekurangan Failover Clustering
Seperti solusi teknologi lainnya, failover clustering membawa manfaat tertentu, tetapi dengan biaya.
Manfaat failover clustering meliputi berikut ini:
- Kehilangan data nol
- Perlindungan seluruh contoh
- Pemulihan cepat
- Failover otomatis
Harga yang Anda bayar untuk manfaat ini adalah sebagai berikut:
- Failover clustering tidak melindungi terhadap kegagalan disk
- Tidak ada standby database tersedia untuk pelaporan
- Khusus Hardware diperlukan
- Failover clustering umumnya mahal untuk diterapkan
- Tidak ada duplikat data untuk laporan atau pemulihan bencana
















0 comments:
Post a Comment