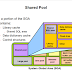
Implementasi

Database mirroring memiliki proses implementasi lebih mudah bila dibandingkan dengan failover
clustering. Hal ini tidak memerlukan konfigurasi hardware khusus dan dapat diterapkan dan dikelola
sepenuhnya melalui SQL Server. Berikut adalah langkah-langkah dasar Anda harus melakukan untuk mengatur
Database mirroring:
1. Buat endpoint untuk komunikasi basis data.
2. Backup database pada server principal.
3. Restore database pada server mirror.
4. Atur server utama sebagai partner pada server mirror.
5. Atur server mirror sebagai partner pada server utama.
Salah satu kelemahan database mirroring dibandingkan dengan failover clustering adalah bahwa Anda harus mengatur mirroring database untuk setiap database, sedangkan pada failover clustering,
seluruh instance diprotect. Karena mirroring dikonfigurasi untuk masing-masing database(principal dan mirror),
Anda harus memastikan bahwa data eksternal yang dibutuhkan oleh database mirror juga tersalin ke
server mirror. Misalnya, Anda perlu menyalin login dari database master pada server principal ke database master pada server mirror,
dan juga memastikan bahwa setiap pekerjaan yang dibutuhkan oleh database mirror
berada di server mirror. Juga, karena database mirroring membuat salinan database, Anda akan
perlu menggunakan dua kali lebih banyak ruang disk dari yang Anda lakukan dengan failover clustering.
Keunggulan Mirroring memiliki salinan duplikat dari database membuat mirroring menjadi solusi yang jauh lebih baik daripada failover clustering ketika Anda khawatir tentang pemulihan bencana dan kegagalan disk. Mirorring dalam SQL Server 2008 termasuk fitur baru. Mirroring yang akan memperbaiki page data yang corupt dengan menyalin page-page tersebut dari partner jika setiap corupt telah terdeteksi.
Snapshots Untuk Reporting
Untuk menggunakan database mirroring sebagai solusi report, Anda juga harus menggunakan fitur database snapshot, yang mengharuskan SQL Server 2008 versi Enterprise. Anda dapat menggunakan
snapshot database dalam hubungannya dengan mirroring database untuk memberikan laporan statis
solusi dengan mengambil snapshot reguler dari database mirror. User tidak dapat terhubung
secara langsung ke database mirror untuk melakukan query, tapi dapat membuat snapshot dari mirror
Database pada waktu tertentu, yang akan memungkinkan pengguna untuk terhubung ke database snapshot.
Dalam rangka untuk menjaga arus data dan ukuran snapshot, Anda harus me-refresh snapshot secara berkala dengan menciptakan snapshot baru dan mengarahkan lalu lintas data di sana.
Kemudian Anda dapat menghapus snapshot lama stelah open transaction selesai semua.
Snapshot database akan terus berfungsi setelah failover terjadi; Anda hanya akan kehilangan konektivitas sementara selama failover database di-restart. Anda mungkin perlu untuk men-drop snapshot dan menangguhkan pelaporan sampai server lain dibawa online.
Redirect dalam Event sebuah Failover
Transparent client redirect adalah fitur yang disediakan dalam Microsoft Data Access Component(MDAC) yang bekerja dengan database mirroring untuk memungkinkan aplikasi client untuk secara otomatis meridirect dalam kasus failover. Ketika melakukan koneksi ke database yang berpartisipasi dalam database mirroring, MDAC akan mengenali ada database mirror dan menyimpan informasi koneksi yang diperlukan untuk menyambung ke database mirror, bersama dengan database utama.
Jika koneksi ke database utama gagal, aplikasi akan mencoba untuk menyambung kembali.
Jika aplikasi tidak dapat menyambung kembali ke database utama, koneksi ke database mirror dicoba. Ada satu peringatan utama ketika bekerja dengan klien redirect transparan:
Aplikasi ini harus terhubung ke database utama sebelum failover telah terjadi untuk menerima informasi koneksi tentang mirror. Jika aplikasi tidak dapat terhubung ke server utama, itu tidak akan pernah diarahkan ke mirror.
Database mirroring memiliki proses implementasi lebih mudah bila dibandingkan dengan failover
clustering. Hal ini tidak memerlukan konfigurasi hardware khusus dan dapat diterapkan dan dikelola
sepenuhnya melalui SQL Server. Berikut adalah langkah-langkah dasar Anda harus melakukan untuk mengatur
Database mirroring:
1. Buat endpoint untuk komunikasi basis data.
2. Backup database pada server principal.
3. Restore database pada server mirror.
4. Atur server utama sebagai partner pada server mirror.
5. Atur server mirror sebagai partner pada server utama.
Salah satu kelemahan database mirroring dibandingkan dengan failover clustering adalah bahwa Anda harus mengatur mirroring database untuk setiap database, sedangkan pada failover clustering,
seluruh instance diprotect. Karena mirroring dikonfigurasi untuk masing-masing database(principal dan mirror),
Anda harus memastikan bahwa data eksternal yang dibutuhkan oleh database mirror juga tersalin ke
server mirror. Misalnya, Anda perlu menyalin login dari database master pada server principal ke database master pada server mirror,
dan juga memastikan bahwa setiap pekerjaan yang dibutuhkan oleh database mirror
berada di server mirror. Juga, karena database mirroring membuat salinan database, Anda akan
perlu menggunakan dua kali lebih banyak ruang disk dari yang Anda lakukan dengan failover clustering.
Keunggulan Mirroring memiliki salinan duplikat dari database membuat mirroring menjadi solusi yang jauh lebih baik daripada failover clustering ketika Anda khawatir tentang pemulihan bencana dan kegagalan disk. Mirorring dalam SQL Server 2008 termasuk fitur baru. Mirroring yang akan memperbaiki page data yang corupt dengan menyalin page-page tersebut dari partner jika setiap corupt telah terdeteksi.
Snapshots Untuk Reporting
Untuk menggunakan database mirroring sebagai solusi report, Anda juga harus menggunakan fitur database snapshot, yang mengharuskan SQL Server 2008 versi Enterprise. Anda dapat menggunakan
snapshot database dalam hubungannya dengan mirroring database untuk memberikan laporan statis
solusi dengan mengambil snapshot reguler dari database mirror. User tidak dapat terhubung
secara langsung ke database mirror untuk melakukan query, tapi dapat membuat snapshot dari mirror
Database pada waktu tertentu, yang akan memungkinkan pengguna untuk terhubung ke database snapshot.
Dalam rangka untuk menjaga arus data dan ukuran snapshot, Anda harus me-refresh snapshot secara berkala dengan menciptakan snapshot baru dan mengarahkan lalu lintas data di sana.
Kemudian Anda dapat menghapus snapshot lama stelah open transaction selesai semua.
Snapshot database akan terus berfungsi setelah failover terjadi; Anda hanya akan kehilangan konektivitas sementara selama failover database di-restart. Anda mungkin perlu untuk men-drop snapshot dan menangguhkan pelaporan sampai server lain dibawa online.
Redirect dalam Event sebuah Failover
Transparent client redirect adalah fitur yang disediakan dalam Microsoft Data Access Component(MDAC) yang bekerja dengan database mirroring untuk memungkinkan aplikasi client untuk secara otomatis meridirect dalam kasus failover. Ketika melakukan koneksi ke database yang berpartisipasi dalam database mirroring, MDAC akan mengenali ada database mirror dan menyimpan informasi koneksi yang diperlukan untuk menyambung ke database mirror, bersama dengan database utama.
Jika koneksi ke database utama gagal, aplikasi akan mencoba untuk menyambung kembali.
Jika aplikasi tidak dapat menyambung kembali ke database utama, koneksi ke database mirror dicoba. Ada satu peringatan utama ketika bekerja dengan klien redirect transparan:
Aplikasi ini harus terhubung ke database utama sebelum failover telah terjadi untuk menerima informasi koneksi tentang mirror. Jika aplikasi tidak dapat terhubung ke server utama, itu tidak akan pernah diarahkan ke mirror.